
李春桃 吉林大学考古学院
“古文字与中华文明传承发展工程”协同攻关创新平台
戚睿华 吉林大学考古学院
“古文字与中华文明传承发展工程”协同攻关创新平台
杨溪 吉林大学人工智能学院
周日鑫 吉林大学人工智能学院
摘要
分期断代是青铜器研究的重要基础,但铜器断代工作具有较高的专业门槛,一直依赖少数专家人工完成。人工智能的迅速发展,使青铜器智能断代成为可能。本文以青铜鼎为对象,提出利用人工智能深度学习技术对先秦时期青铜器进行断代的方法,并从数据处理、模型搭建、具体实验、结果分析等多个角度展开研究。实验结果表明,人工智能模型能够准确判断绝大多数青铜鼎的时代。同时,研究成果也已转换成实际应用,模型已经部署于微信小程序。
关键词:青铜器 断代 人工智能 应用
青铜器在中国先秦时期具有举足轻重的地位,所以夏商周三代又被称作“青铜时代”。青铜器研究对于考古学、历史学、文字学都有着积极的意义,而青铜器的分期断代又是青铜器研究的重要部分。只有在分期断代基础上,青铜器才能成为有效的史料。郭沫若对此曾有专门讨论:“时代性没有分划清白,铜器本身的进展无从探索,更进一步的作为史料的利用尤其是不可能。就这样,器物愈多便愈感觉着浑沌。”[1]其说甚是,这充分说明了分期断代在青铜器研究中的重要性。
追溯历史,汉代便有青铜器出土,但数量极少,尚不具备深入研究的条件。宋代金石学兴起,青铜器的研究也开始起步,宋人更多集中于青铜器的搜罗与著录,研究水平并不突出。清人在这一领域的认识已颇为深入,然而他们更重视金文,对于青铜器本身,尤其青铜器年代的讨论较少,没有形成一定的规模。真正科学的青铜器分期断代研究是从20世纪30年代开始,郭沫若在《两周金文辞大系》中提出“标准器断代法”,即先根据铭文内容确定某件器物的年代,以此作为标准器,再去系联和推定那些与标准器在铭文内容、器物形制、花纹特点等方面相关的器物的时代。[2]此方法的提出为青铜器的断代奠定了科学的基础,也被当时的学者广泛接受。其后陈梦家、唐兰等人又做了进一步的阐述。[3]随着考古学的逐步发展、完善,又出现了综合运用类型学与地层学对青铜器进行分期断代的方法,即在某一类青铜器内划分出“型”和“式”,总结出每期铜器的器形、花纹特点,再结合相伴出土的陶器,并与考古单位中的地层关系的分析相互对应,进而确定青铜器的年代。[4]
上述两种方法各有特点,在遇到具有长篇铭文且记载时代明确的器物时,第一种方法更为有效,有时甚至能够确定器物的绝对年代。而面对只有短篇铭文或无铭的青铜器时,后一种方法更为适合。当然,两种情况不是绝对的,很多时候是两种方法并用。若想对青铜器进行准确的分期断代,既需要掌握专业的考古学知识,也需了解专门的古文字学知识。再加上青铜器的类别多、数量大,青铜器断代难度非常大,导致只有少数专家才精通这一研究领域,普通大众想要快速了解某件器物的时代颇为不易;外专业研究者若要使用某件铜器作为参考资料,也需花费大量时间去翻查相关书籍。
近年来人工智能发展迅速,尤其是深度学习技术,具有学习、分析、总结的能力,能够对文字、图像和声音等数据进行识别、归纳与分类。鉴于深度学习技术已经具备了分析图像的能力,所以已有学者将人工智能运用到文物研究当中,如利用人工智能技术缀合甲骨残片,[5]开展陶瓷器物断代工作等。[6]同样,也可考虑利用人工智能技术开展青铜器的分期断代工作。以上介绍的标准器断代法和类型学与地层学结合法,两者的共同点是都需要根据青铜器的客观外在形态将器物系联起来,器物的形状、花纹等外在特征是建立系联的关键所在。而深度学习技术擅长发现样本的内在特征、挖掘样本的变化规律,进而完成数据的辨识与分类,这与专家根据器物的特征进行断代在方法上具有一致性。可见,利用人工智能深度学习技术开展青铜器的分期断代研究在方法上是可取的。
在明确了可行性后,经过近两年的努力,我们收集并标注了大量数据,搭建了深度学习智能模型,完成了实验,并推出了可实际应用的智能断代程序。目前已经完成鼎、簋等食器部分的工作。篇幅所限,下面先就青铜鼎的情况开展介绍。此处需要说明的是,本文面向的群体主要是人文学科研究者,行文时会尽量采用文科论文的表述方式,一些繁琐的计算公式和人工智能层面的技术研究详参另文。下面便从科学研究和应用实现两个方面展开讨论。
一 科学研究
鼎是青铜器中数量最多的器类之一,其发展贯穿整个先秦时期:在数量方面,具备交叉研究的基础;在时代跨度方面,具有交叉研究的空间。我们主要利用基于深度学习模型的图像识别和细粒度分类方法,提取并分析样本特征相似度,融合青铜器的专业知识开展研究。对于人工智能技术而言,青铜器分期断代本质上是一项分类任务,但与其他分类任务也存在区别,即青铜器数据是一个专业性较强的数据集,其中很多细微特征需要依靠专业知识才能分辨清楚。因此我们在数据处理、属性标注、模型搭建等方面都尽量考虑到青铜器数据自身的特殊性。
1、数据收集与标注
在数据收集方面我们目前使用的是青铜鼎的二维图像。数据均取自正式的出版书籍或发掘报告,还有一些使用了公开的数据库资源。其中大型著录书籍包括《中国青铜器全集》[7]《商周青铜器铭文暨图像集成》《商周青铜器铭文暨图像集成续编》《商周青铜器铭文暨图像集成三编》[8]《中国出土青铜器全集》等,[9]以及其他一些青铜器图录与考古发掘报告。另外,“中研院”历史语言研究所金文工作室研发的《殷周金文暨青铜器资料库》中有的青铜鼎图版存在不同副本,[10]若有不见于其他著录书籍的副本,也予以收录。这部分材料在数据集中所占比例虽然不大,但是却可呈现出同一件器物的不同角度,颇为重要。为了尊重、彰显收藏单位或整理者所做的工作,我们在所开发的应用程序中为使用的每一件器物都标注了出处(详后文)。
在图像类别的选用上,收录范围包括器物的彩色照片、黑白照片、线图摹本、全形拓等多种形式。其中彩色照片占绝大多数。线图摹本主要取自宋人、清人的著录。由于多数线图存在较大程度的失真,所以我们对线图进行了筛选,选取其中效果较好、摹写相对准确的图像。全形拓图像使用得最少。线图摹本和全形拓在一定程度上会对人工智能模型造成干扰和障碍,影响模型的准确性。由于研究成果终会转化成实际应用,考虑到实际使用情况,我们仍将这两类图像收录其中。
目前共收集青铜鼎图片样本3690个,每一个样本都结合学界的研究成果作了时代标注。共分为11个时代,具体包括商代早期、商代晚期、西周早期、西周中期、西周晚期、春秋早期、春秋中期、春秋晚期、战国早期、战国中期、战国晚期。很多著录对所收器物已给出了断代意见,其判断无误者,我们直接承袭;其中明显有误者,我们对其做了校正,径直给出正确的年代;而年代存在争议的器物,我们择善而从。某些书籍本身并未对器物的年代进行详细划分,如《中国出土青铜器全集》一书,多数情况下只是给出器物的模糊年代。面对这种情况,我们会进一步给出更为详尽的判断。如该书第一卷第18号收录的一件圆鼎(见封三图1),时代标注为“西周”,[11]据其器形、花纹可知此鼎时代为西周早期,所以此器的年代标签为“西周早期”。总之,收录数据过程中会尽量结合学界已有的研究,为每一张青铜鼎的图片标注出时代信息。
器物形制是分期断代的基础,所以我们也对青铜鼎的形制特征进行了标注。由于不同学者对青铜鼎的器形分类不同,对器物花纹的称呼也存在差异。参考已有的青铜器研究,[12]我们将青铜鼎的形状概括为29种,将花纹概括成67种。在具体标注时,口沿、腹部、足部等不同部位的花纹分别标注。将鼎耳的类型分为5种,鼎足的类型分为8种,另扉棱、盖钮等也分别进行了划分,利用工具进行了标注。例如伯鼎(见封三图2),[13]该器的标签共15个:其中鼎足4个,标签为“鸟形扁足”;鼎耳2个,标签为“立耳”;腹部纹饰共两组,第一组标签2个,为“独体兽面纹”(一在正面,一在侧面),第二组标签2个,为“直身夔龙纹”(均在正面);扉棱共5组,标签为“F形扉棱”。再如师汤父鼎(见封三图3),[14]该器的标签共12个:其中足部3个,标签为“蹄足”;耳部2个,标签为“立耳”;腹部纹饰共两组,标签为“大鸟纹(回首)”;颈部纹饰共两组,标签为“长尾鸟纹”;颈部扉棱共两组,标签为“平直扉棱”。我们对目前所收集的全部青铜器都做了如上标注。

封三图1 圆鼎

封三图2 伯鼎

封三图3 师汤父鼎
在数据分配方面,我们按照4:1:5的比例将整个数据集划分为训练集、验证集、测试集。此处需要说明的是,在我们的划分比例中,训练集的数据占比较低,而测试集的占比较高。更少的训练数据、更多的测试数据会增加模型的学习难度,不过能够更全面准确地检测模型的断代效果,从而更有效地测试出该方法的有效性以及局限性。
2、数据扩充与增强
为了使模型得到足够的训练,我们在研发过程中对数据进行扩充与增强。增强方式主要通过去除背景、灰度化、线条化和翻转图片等(见封三图4)。限于篇幅,此处仅略述灰度化与线条化两种方式。首先介绍灰度化的处理过程,任何颜色都由红、绿、蓝三原色组成,这三种颜色分别对应三个通道,而三个通道的每个数值取值在0-255之间。将彩色图转化为灰度图,也就是将原本的红绿蓝三色通道合并为一个通道,最终将彩色图版变成了质量较高的灰度图版,实现了扩充数据的目标。将彩色图版进行灰度处理,除了可以增大数据量外,对于那些本身只公布过灰度图片的青铜鼎的时代判断有较大帮助。

封三图4
线条化处理的关键在于识别图版中的线条,也就是找出图片中物体的轮廓和花纹信息。轮廓和花纹部位的像素值与其它部位的不同,非轮廓和非花纹部分的像素值是连续的,可以用高斯模糊的方法得到非线条部分。在原始图片中减去非线条部分,即可得到原始图片的线条,进而实现数据的扩充(见封三图5)。通过彩色图版的线条化,除了可以增大数据量外,对于判断那些只存在线图摹本的青铜鼎的时代有一定的帮助。

封三图5
通过以上方法,我们成功地对数据进行了增强与扩充,进而增加了训练的数据量。同时,利用这些增强后的数据进行训练也可提高模型的泛化能力,使其可以处理更为复杂的问题。
3、模型搭建与实验
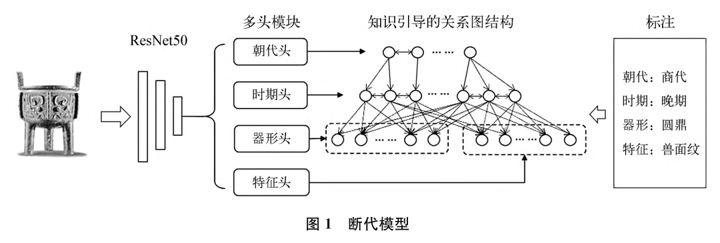
针对青铜器的特殊性,我们搭建了一个用于分类断代的深度学习模型。断代模型如图1所示,在模型中使用ResNet50作为骨干网络,然后将ResNet50编码后的特征向量输入四个头:朝代头、时期头、器形头、特征头。其中朝代头和时期头作为多粒度分类的输出,分别预测输入青铜器所属的朝代和时期。器形头和特征头分别预测输入青铜器的单标签器形和多标签特征。同时,通过联合朝代、时期、器形、特征等标注信息,我们建立一个知识引导的关系图结构,使得朝代和时期之间可以相互辅助学习,以将器形和特征等类型学上作为断代依据的重要信息嵌入学习过程中。因为要依据器形和特征等综合因素进行断代,所以我们改进了概率分类的损失函数,从而最大化实现器形、特征与时代间的对应关系。[15]
在建立模型之后,便可利用数据对模型展开训练。[16]如图2所示,基于深度学习的青铜器断代过程可分为训练和预测两个步骤。首先,将完成标注的青铜器数据分成训练集、验证集、测试集三个部分。在训练过程中,使用训练集和验证集对深度学习模型进行训练和选择。利用之前已经设计好的嵌入知识的深度学习模型,实现青铜器的断代任务。通过输入训练数据,不断优化和反复迭代更新模型的参数,得到可以充分提取青铜器断代特征的已训练模型。此后,在预测过程中,将待预测的青铜鼎图像输入已训练模型,就可以得到智能模型所做出的判断结果。
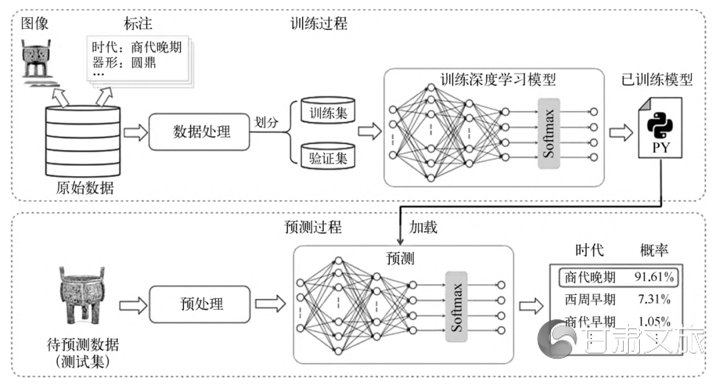
图2 基于深度学习的断代过程
4、测试结果
经过测试,我们发现经过训练的模型已经具备独立的断代能力。在利用测试集进行测试时,在绝大多数情况下都能给出准确的断代意见。我们可以通过粗略时代和详细时代两种划分方式观察测试结果:粗略时代划分,即把所有器物按照商代、西周、春秋、战国四个大的时代进行区分,按照这种方式,模型的总体精度(Overall Accuracy)为88.79%;详细时代划分,即前文所述的11个时代划分,按照这种方式,模型的总体精度为78.83%(以上详细数据参表1);这说明了利用人工智能技术可对青铜器进行分期断代,而且深度学习模型还展现出较强的学习断代能力。
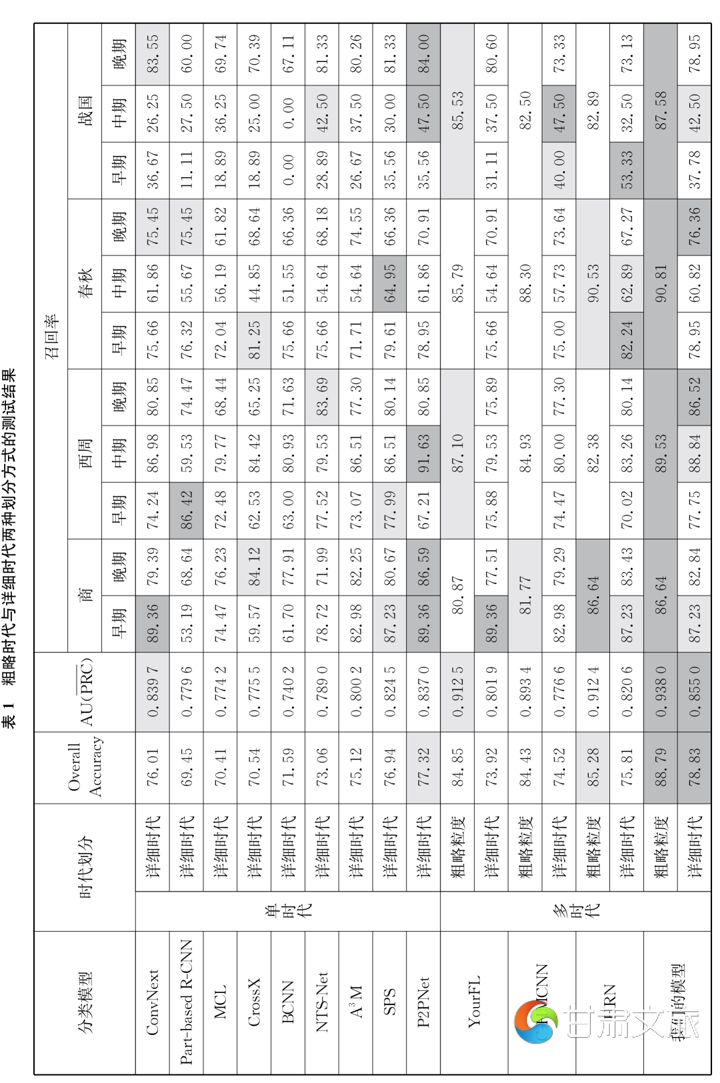
为了说明模型的断代能力,我们对比了其它12种最新的分类模型,利用同样的测试集、训练集、验证集对这些模型进行训练、测试,得出的对比结果如表1。[17]按照粗略时代测试,我们的模型在商代、西周、春秋、战国四个时代上的正确率都排在了第一。按照详细时代划分,我们的模型有2个时代的准确率排在第一;有3个时代的准确率排在第二,在平均准确率上,我们的模型也排在第一。而在总体精度(Overall Accuracy)和AU(PRC)方面,我们的模型也均处于第一的位置。这充分说明我们构建的模型获得了最好的断代结果。
5、结果分析
从总体上看,人工智能模型对青铜鼎的分期与断代能够给出很好的判断。与此同时,对相关结果进行分析会给我们带来更多的启发与思考。经过分析与总结,我们发现影响模型准确率的因素包括训练数据量的多少、图版的清晰度、图片的完整度、东周时期不同地域器形发展快慢差异、相邻时代器形相似程度等几个方面。
从表1所列数据不难看出,人工智能模型对不同的时代的数据测试结果存在差异。其中,准确率最低的是战国早期和战国中期,其最主要的原因就是训练数据总量少,两者数据中训练集数量分别只有31张和34张图版,较其他时代的数量少很多。这使得模型可学习的样本不够丰富,测试结果准确率偏低。如果后期对数据进行进一步补充和增强,测试结果应该会得到明显提升。
当然,如果训练数据不够充分,但是数据中的器形具有明显的区别特征,模型完全能够给出准确的判断。如商代早期的训练集数量是37张图版,但是测试的准确率高达87.23%,结果并未受到训练数据不足的影响。这是由于商代早期青铜鼎器形特征十分明显,例如商代早期青铜鼎的尖锥足(图3a)、方体深腹直壁(图3b)等特征是其他时代的青铜鼎很少具备的,而模型能够捕捉到这些特征并以此为依据进行分类。相对而言,战国早期和中期的青铜鼎在器形上与相邻时代的器物有很多相似性,加上训练集中这两个时代的数据本就不多,能提取到的特征也会受到限制,而这些特征有的还与其他时代的器物相近,这就使得这两个时代的准确率偏低。
纹饰的风格及清晰度对模型测试准确率可能也造成了一定的影响。分析实验结果可以看出:自商代至春秋早期这六个时段较春秋中期至战国晚期这五个时段人工智能模型的准确率高出很多。前者的平均准确率为83.69%,后者为59.28%,相差20多个百分点。推敲其原因,应当与鼎的花纹变化有着密切关系。商代至春秋早期青铜鼎上所施加的花纹图像往往较大,如较早流行的兽面纹(图3c)、鸟纹(图3d),稍晚流行的环带纹、[18]窃曲纹、重环纹,整体上图画性更强,智能模型也更容易辨识。而自春秋中期开始,流行的是蟠螭纹(图3e)、蟠虺纹(图3f),这两种花纹或呈带状,或布满于器表,而不像兽面、鸟形那样在器表上呈独立的图案,所以智能模型不易捕捉到这类纹饰的特征。如果数据集中图像清晰度稍差,蟠螭纹与蟠虺纹甚至都无法体现出来。所以,智能模型对春秋中期以后青铜鼎的判断准确率不如春秋中期以前的时段高。

图3
青铜鼎图片的清晰度会对模型测试准确率产生影响。如器形模糊,尤其是测试集数据中有的图版与背景颜色区分不够明显(如图3g),会形成辨识障碍,智能模型可能会把某些背景误认作器物的一部分。除此之外,器物的拍摄角度也会对辨识产生影响,如俯视拍摄与直视拍摄会使同一件鼎在图版上呈现出不同的效果,俯视拍摄的图版鼎足往往会显得略短,与数据集中绝大多数的正面拍摄照有所不同,所以在一定程度上造成器形失真,进而影响模型的识别准确率。
图版中器物的完整性也会影响模型测试准确率。在收集数据时,为了保证数据的多样性、全面性,我们将部分器形残缺的青铜鼎图版也收录在数据集中。一旦这些残缺器形被划分到测试集中,由于残缺器形的数据总量很少,模型无法得到充分训练,可能会对模型判断形成干扰。如曾子倝鼎(图3h)被划分到测试集中,[19]从器形上看,属于典型的春秋早期的曾国青铜鼎。该器三足残缺,导致与其他常规鼎的形制略异,测试时模型将其判断成西周晚期,其错误原因或许与器足缺失有很大关系。为了证明这一点,我们结合曾国早期其他青铜鼎的形制,试着将该器的三足加以复原,[20]形成一幅器形完整的图版(图3i),重新利用模型进行测试,结果显示模型将其准确地判断为春秋早期,器形的完整程度对模型分类的影响由此可见一斑。
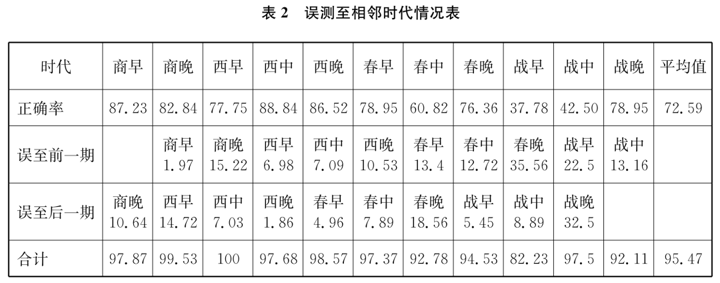
相邻时代器形的相似程度是影响模型准确率的最大因素。我们知道不同时代的青铜鼎在器形、花纹等特征上存在差异。然而,器形及花纹的演变不是一蹴而就的,而是渐变的,这就导致相邻时代之间器物的外在特征有很多相似之处。如商代晚期和西周早期某些青铜鼎极其相似,专家在判断时,也容易出现误差,人工智能模型同样如此。我们注意到西周早期青铜鼎样本数量在训练集中占比较大(340件),比西周中期(171件)、西周晚期(111件)的训练数据分别多出一倍或两倍。但预测准确率数为77.75%,反倒不如西周中期的88.84%、西周晚期86.25%高。其主要原因就是西周早期和商代晚期部分青铜鼎的器形十分相似,有很多特征是两个时代所共有的,专家在判断时即使结合铭文或者墓葬信息及伴出器物,有时仍无法给出确定的意见。对某些器物只能模糊处理,判定为“商末周初”。[21]所以人工智能模型仅凭借器物外部特征进行断代,也会出现误差。我们提取后台测试数据进行总结,发现西周早期青铜鼎的准确率为77.75%,而有15.22%预测为商代晚期,后者正好属于兼具商代晚期与西周早期两种特征的数据。如果把这些算入,西周早期的准确率就达到了92.97%,无疑是相当高的。同时,从这一点也看出:模型对于商周之际的部分青铜鼎与人脑一样难以作出准确区分,两者的出错点是相同的。这也从另一方面说明,经过专业训练的模型能够具有同专家相仿的能力。为了说明问题,我们把预测到相邻时代的错误数据进行了统计,得出结果可参表2。若把误测到相邻时代的情况也算入的话,平均准确率可达95.47%,可见模型所预测的错误数据,多数都误判入相邻时代,这说明模型是能够捕捉并获取器物的主要特征。
当然,如果器物具有某种细微的特征,这种特征恰好可以区分时代的话,模型有时也能捕捉并进行有效判断。以柱足直壁方鼎为例,[22]这类鼎器腹呈方形,立耳,柱足,器腹有时饰兽面纹,颈部饰单首双身龙纹,有时腹部两侧和底部饰乳钉纹。此类方鼎在商代晚期、西周早期、西周中期都有出现,但主要流行在商代晚期和西周早期。若仅着眼于器形,其时代有时不易判断。但其中有一种鼎腹带有“F”形扉棱的叔虞方鼎(图3j),[23]绝大多数都在西周早期。[24]而我们在测试过程中发现,智能模型在测试这种“F”形扉棱柱足方鼎时,绝大多数都能做出正确的判断。可见,模型已经捕捉到了这种细微的区别。
以上我们对深度学习模型的测试结果进行了分析,最终的结论是模型能够正确的判断绝大多数青铜鼎的时期。由于青铜器分期断代是一项复杂的工作,比较依赖专家的主观研究经验。对同一件器物的时代,不同学者往往会有不同的断代观点。[25]经验丰富的学者尚且如此,其难度可见一斑。而人工智能模型能够胜任这项工作,同时能够与人脑体现出相同的特性,这是十分难得的。
二 应用实现
1、应用系统实现方式
科研可以推进应用的发展,而应用又是科研成果的最好体现,所以将科研成果转换成实际应用也是我们的主要目标之一。
我们将经过训练的人工智能模型部署到了微信小程序中。由于微信小程序具有便捷性、兼容性、易安装、易传播等优点,所以我们将其作为青铜器智能断代程序的首选载体。微信小程序后端的实现方式多种多样,考虑到与人工智能模型的一致性,我们采用Python语言作为后端语言并基于Flask框架加以实现,从而完成了小程序的部署。
2、应用系统组织结构
本系统具有两个主要功能:一是青铜器智能辨类与断代;[26]二是青铜器数据库(功能示意图可参图4)。前者智能断代部分包括对青铜器的自动断代和对青铜器特征部位的自动检测。我们使用两个不同的智能模型来实现上述两种功能:一个是上文已经讨论的深度学习模型,在经过了训练之后,能够自主判断青铜器的年代;另一个模型则专门用来检测青铜器的特征,并给出相应的名称,如纹饰、器形等等。
青铜器数据库方面,本系统提供了我们所收集并标注的数据集,并且做了分类与断代,使用者可分别按照器类或者时代浏览相关器物图像。为了用户便于核对图像出处,也为了尊重器物的收藏单位及材料发布者,我们为每张图像做了信息表,标明了器物的著录书籍、名称、时代、出土地、现藏地等相关信息。以上数据可为使用者提供很大的便利。
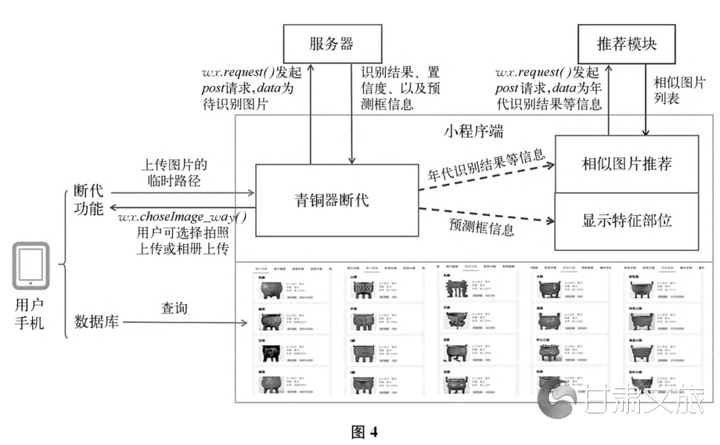
3、应用系统显示说明
系统初始界面由“程序名称”“拍照/上传照片”“数据库”“研发说明”组成(参图5a)。其中“吉金识辨·青铜器智能断代与辨类”是本程序的名称,在微信小程序中搜索名称中的关键字可以检出本程序并进行使用。
“拍照/上传照片”是上传待测试图版的两种途径。前者针对现实场景中的青铜器图版,可供拍照上传;后者针对客户终端设备中已经存储的青铜器图版,可供选择上传。
“数据库”是我们搜集并标注的青铜器数据,可分别按照时代或者类别进行浏览。目前仅上传了青铜鼎数据。每一件器物的图版都有相关信息介绍,根据实际情况列出器物名称、著录出处、器物时代、出土墓葬、现藏地等(参图5b)。
“研发与说明”是关于研发团队的介绍,以及使用书籍的简称等。
在具体使用时,如果上传的图版较大,速度会略有延迟。上传后智能模型会进行类别和时代的判断。其中的断代结果,模型会给出一个最优结果和两个次优结果,以供参考。结果下面都给出“可信度”,以百分数表示,按智能模型的判断可信度由大至小排列。如以近年新出土的曾侯谏鼎(图5c)为例,将该形上传到本系统中,系统会给出识别结果(参图5d)。其中最上面的图像为识别器形,框内为智能模型自动检测的器形、花纹特征。“器类”的结果是“鼎”。下面的“断代结果”中,“西周早期”是最佳结果,可信度达91%,而“商代晚期”和“西周中期”是参考结果,可信度分别为9%和0%。那么毫无疑问,“西周早期”是人工智能模型为曾侯谏鼎的做出的断代结果。同时,小程序还设置有“反馈”功能,使用者可以输入自己的意见,提交并反馈给后台,我们收到后会进行相应处理。
为了给使用者以足够的参考信息,充分发挥出本系统的学术价值,我们特意设置了“相似器型推荐”功能。该功能会提供5个与用户所上传的青铜鼎图版器形、纹饰均相似的器物,展示出这些参考器物的出处、器名、时代、出土地、现藏地等信息,使用者可根据相关信息,核对原始资料,并加以引用。每件器物都可以点击进入,查看详细信息。仍以曾侯谏鼎的断代为例,图5d下部有“相似器型推荐”,为用户智能推荐了5个与测试图版相似的青铜鼎器形,其中上面右数第二张图版就是曾侯谏鼎本身,因为之前的数据集中收录了该器,所以会被推荐出来。这5个相似器形图版都可以点击后进一步查看,如点击图5d下部相似推荐器形中的下面右数第二张图版,即可查看其详细信息(参图5e)。此鼎器形的图版上方,我们为该器标注的形制特征都会通过标签显示出来。如两个“立耳”、三个“柱足”、两组“兽面纹”等。此器的其他信息会在图版下部列出,如“名称:伯鼎(伯作宝彝鼎)”;“年代:西周早期”;“出土地:1985年平顶山应国墓地M48:1”;“现藏地:平顶山博物馆”;“出处:出土全集9.230”。[27]通过器物名称及出处,便可直接进行核实与引用。“相似器型推荐”中每一件器都标注了如上信息[28]。
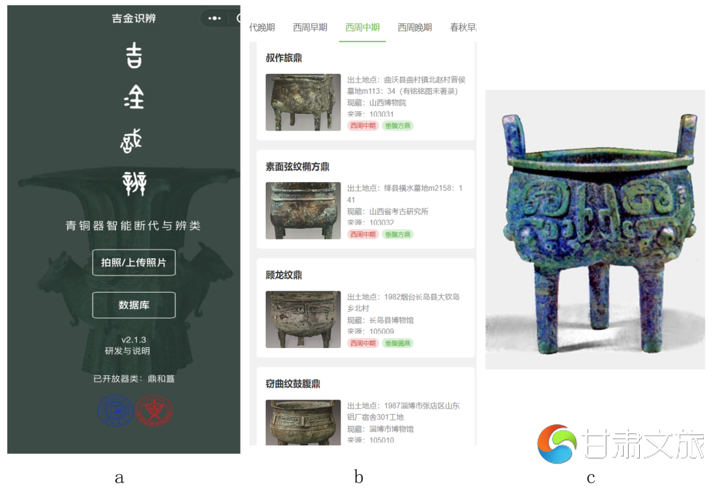

图5
4、应用系统功能作用
下面从具体使用的角度谈一谈本系统的价值。首先,“数据库”可以按照器类、时代等分类进行浏览,为用户了解和熟悉青铜器提供便利。使用者想要了解某一种器类或某一时代的器物都可通过“数据库”实现。将来我们还会逐步提供检索功能,包括通过器名、出土地、花纹或器形等关键词检索,尽可能为用户提供最大的便利。
其次,为器物的断代提供帮助。本系统的核心包括青铜器数据的搜集标注和深度学习模型的研发,其最终目的是使深度学习模型具有像人脑一样的专业判断能力,能够对青铜器进行自动的分类与断代。目前从青铜鼎、青铜簋等器类的研发来看,这项工作已经达到预期目标。系统能够给普通用户提供帮助,也能为专业研究者提供参考。当遇到新见的青铜器时,可以使用本系统进行断代,本系统中经过训练的智能模型会给出断代结果,并检测出器物的主要形制特征。同时,“相似器型推荐”功能所推荐的相似数据,也具有一定的学术参考价值。
再次,为青铜器的信息核查提供帮助。过去学者对青铜器信息的掌握主要依靠记忆。例如,当面对一件已被著录的青铜器图版,而器物缺少著录信息,想要知道此器出自哪一座墓葬,在哪一部书籍中曾有著录,过去只能依靠学者的记忆力。而本系统却可提供直接帮助,前提是待核查的器物在我们所收集的数据范围之内。绝大多数情况下,只要人工智能模型利用了某些数据做了训练,当同一张青铜器图版再一次出现,上传到本系统后,在“相似器型推荐”功能中基本都可将相同器物推荐出来。因为我们对推荐器形的相关信息做了详细标注,使用者便可直接找出器物的相关信息。在保证准确的同时,还能提高效率。
下面我们以一个具体的例子来说明本系统的功用。吴镇烽先生《铭图》966号著录一件“后母辛鼎”,其附有器形、铭文图版(参图6a、6b),[29]据该书“出土时地”介绍,此器的出土信息是“1976年河南安阳市小屯村(今属殷都区)殷墟妇好墓(M5.809)”。核查此鼎的著录文献如《殷墟妇好墓》、[30]《考古学报》[31]可知,安阳殷墟妇好墓(M5.809)确实是“后母辛鼎”,铭文也与《铭图》966号(图6d)相同,但是其正确的器形却是图6c,与图6a完全不同。据此可知《铭图》一书配图有误,吴镇烽先生在后来编著的《金文通鉴》检索系统已经将器形图进行了替换更正。[32]那么图6a这张青铜鼎图版出自哪里呢?为何会被错配呢?吴先生的《金文通鉴》并未交代。其实利用“吉金识辨·青铜器智能断代与辨类”即可解决此问题。通过微信小程序打开本系统,将图6a上传到系统中,智能模型会自动给出器物的时代以及推荐出五件相似器形(参图6e)。从推荐的器形中我们可以发现,最左面和右上角两件器物与检测的青铜鼎十分相似。点击打开详细信息可知,这两个图版对应同一件器,都是妇好方鼎,只是著录书籍不同,所用的图版也存在差异,前者著录于《铭图》503号(图6f),后者著录于《全集》2.40(图6g),[33]对比可知,图6a即是妇好方鼎无疑。因为该器与“后母辛鼎”两者都出土自殷墟妇好墓,所以才被误配图形。
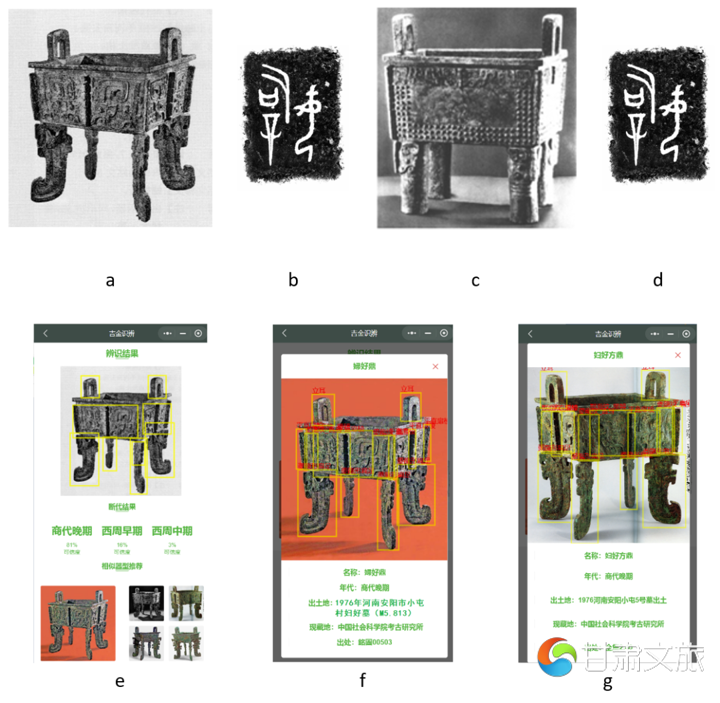
图6
三 结论
人工智能发展迅速,已经参与到很多科研工作当中,但是将人工智能与青铜器的分期断代研究结合起来尚属首次。[34]通过实验我们发现,经过训练后的人工智能模型可以对青铜鼎的时代进行独立的判断,并且能够保证较高的准确率。与此同时,我们也把科研成果直接转换成了实际应用,希望可以对青铜器的研究提供便利与帮助。
注释
* 本文是“古文字与中华文明传承发展工程”资助项目“基于人工智能技术的青铜礼器断代研究”(G1903)阶段性成果,并得到吉林大学“学科交叉融合创新”项目(批准号:JLUXKJC2021ZY04)、“学科交叉青年创新团队”项目“基于视觉智能的青铜器综合研究”的资助。
[1]郭沫若:《青铜器时代》,《青铜时代》,北京:科学出版社,1957年,第301页。
[2] 郭沫若:《两周金文辞大系》,手写影印本,1932年,第7页。
[3] 陈梦家:《西周铜器断代》(一至六),《中国考古学报》1949年第9-10册(合订本)、《考古学报》1956年第1-4期,后连同未发表稿被整理成著作《西周铜器断代》,北京:中华书局,2004年;唐兰:《西周青铜器铭文分代史征》,北京:中华书局,1986年。
[4]邹衡:《试论殷墟文化分期》,《北京大学学报(人文科学)》1964年第4-5期;李丰:《黄河流域西周墓葬出土青铜礼器的分期与年代》,《考古学报》1988年第4期。
[5]莫伯峰、张重生、门艺:《AI缀合中的人机耦合》,《出土文献》2021年第1期,第19-26页。
[6] 冯金牛等:《基于卷积神经网络的中国古陶瓷智能断代研究》,《陶瓷学报》2022年第1期,第145-151页。
[7] 中国青铜器全集编辑委员会编:《中国青铜器全集》,北京:文物出版社,1994-1998年。
[8]吴镇烽编著:《商周青铜器铭文暨图像集成》,上海:上海古籍出版社,2012年,以下简称“《铭图》”;吴镇烽编著:《商周青铜器铭文暨图像集成续编》,上海:上海古籍出版社,2016年;吴镇烽编著:《商周青铜器铭文暨图像集成三编》,上海:上海古籍出版社,2020年。吴镇烽先生编著的这三部著作有配套的电子检索系统《金文通鉴》,本文多数青铜鼎的照片我们取自该系统。
[9]李伯谦主编:《中国出土青铜器全集》,北京:科学出版社、龙门书局,2018年。
[10]“中研院”历史语言研究所金文工作室:《殷周金文暨青铜器资料库》。
[11] 李伯谦主编:《中国出土青铜器全集》,第1卷,第17页。
[12]上海博物馆青铜器研究组:《商周青铜器文饰》,北京:文物出版社,1984年;王世民、陈公柔、张长寿:《西周青铜器分期断代研究》,北京:文物出版社,1999年;彭裕商:《西周青铜器年代综合研究》,成都:巴蜀书社,2003年;朱凤瀚:《中国青铜器综论》,上海:上海古籍出版社,2009年;彭裕商:《春秋青铜器年代综合研究》,北京:中华书局,2011年;彭裕商:《战国青铜器年代综合研究》,成都:巴蜀书社,2018年。
[13]《铭图》,第2卷,第1006号。
[14]中国青铜器全集编辑委员会编:《中国青铜器全集》,第5卷,北京:文物出版社,1997年,第26页,29号。
[15]关于模型的搭建等技术问题此处仅略作交代,详参:Rixin Zhou, Chuntao Li, Xi Yang, et al, Multi-Granularity Archaeological Dating of Chinese Bronze DingsBased on a Knowledge-Guided Relation Graph,CVPR2023。
[16] 为了对比效果,我们首先训练的是只有时代标签的图像数据,其他标签如器形、花纹等均未放入,训练结束后进行了测试;随后我们又训练了既有时代标签,同时也有器形、花纹特征标签的数据,训练结束后同样进行了测试。结果显示,按粗略时代划分,后者较前者的准确率高出1.94%;按详细时代划分,后者较前者的准确率高出1.78%。可见加注多种标签的数据测试结果更优。所以我们在研发过程中使用的是加注多种标签的数据。在实际应用中,标注并显示出青铜器的器形以及花纹等特征更便于使用和参考。
[17]表中各项结果为百分数,%省略。下同。深色阴影数值者排名第一,浅色阴影者排名第二。人工智能领域更多使用“精度值(precision)”来体现模型的预测能力。为了便于文科读者理解,我们此处使用“召回率(recall)”来表现模型的预测能力,即每一类预测准确的数值除以相应的数据总量所得出的百分比,也就是我们通常所说的准确率。表格中的数值即由此得出。
[18]李零先生据新出霸伯器铭文将环带纹称作山纹。参李零:《山纹考——说环带纹、波纹、波曲纹、波浪纹应正名为山纹》,《中国国家博物馆馆刊》2019年第1期。
[19] 此鼎著录于《铭图》2388号。
[20]复原过程中主要参考了曾国早期同类青铜鼎的形制,三足取自曾子仲鼎(《铭图》2214)。曾国此类青铜鼎有着极为鲜明的地域特色,相关讨论参王恩田:《上曾太子鼎的国别及其相关问题》,《江汉考古》1995年第2期;张昌平:《曾国青铜器研究》,北京:文物出版社,2009年,第127页。
[21]如吴镇烽先生在《铭图》中将这部分器物标注为“商代晚期或西周早期”。
[22]杨宝成、刘森淼:《商周方鼎初论》,《考古》1991年第6期。此处所讨论的即该文所谓的方体柱足鼎,参该文中的A型方鼎。
[23]叔虞方鼎照片取自2018年北京大学赛克勒考古与艺术博物馆120年校庆特展“寻真——北京大学考古教学与科研成果展”。
[24]陈士松:《商周青铜方鼎研究》,硕士学位论文,湖南大学,2014年,第31、57页。
[25] 如黄鹤先生曾将西周青铜器诸家不同的断代意见做过集中收录。参黄鹤:《西周有铭铜器断代研究综览》,上海:上海古籍出版社,2021年。
[26]“辨类”指自动辨识青铜器的类别。如用户分别上传青铜鼎、青铜簋的图片,模型会自动辨识出图片对应的器类。
[27]“出土全集”在本系统中是《中国出土青铜器全集》一书的简称。此图版参李伯谦主编:《中国出土青铜器全集》,第9册,第218页,230号。
[28] 部分传世器物出土地或现藏地不明确者除外。
[29]《铭图》,第2卷,第237页,966号。
[30]中国社会科学院考古研究所:《殷墟妇好墓》,北京:文物出版社,1980年,第37页。
[31]中国社会科学院考古研究所安阳工作队:《安阳殷墟五号墓的发掘》,《考古学报》1977年2期,图4.3、图版18。
[32]需要说明的是,《金文通鉴》更正的配图也是有问题的。下面略作介绍,殷墟妇好墓一共出土了两件大方鼎,其中第一件编号为789,第二件编号为809。《铭图》966号著录的是编号为809的那件;而《铭图》965号著录的是编号为789的那件。《铭图》966号误配妇好方鼎图版,《金文通鉴》更正成了编号为789的图版,所以《金文通鉴》的修改也不正确。同时,由于《金文通鉴》误用了编号789的图版(即《铭图》965),相应地又把965的器形错配成了司母戊鼎的图版。
[33]“《全集》”在本系统中是《中国青铜器全集》的简称。此鼎图版参中国青铜器全集编辑委员会编:《中国青铜器全集》第2卷,北京:文物出版社,1997年,第40-41页,第40号。
[34]在工作的进展方面,目前我们对青铜鼎、青铜簋的断代工作已经完成,并实现了应用转化。其他食器也已经完成智能断代工作,将会在近期完成应用实现。与此同时,我们也正在开展酒器、水器、乐器、兵器的断代工作,计划在未来一段时间完成全部器类的研发。 来源 :《出土文献》2023年第3期
本文采摘于网络,不代表本站立场,如果侵权请联系删除!




